Football Striker Segmentation
Football Striker
Segmentation
A machine learning model built to isolate exactly what makes a striker elite. I used K-Means clustering and logistic regression to turn 500 players' raw stats into a predictive classification system.
Scouting a striker usually stops at looking at how many goals they scored last season. That's a flawed metric. I wanted to see if statistical modeling could strip away the bias. By clustering 500 players based on secondary metrics like hold-up play and passing consistency, I built a classification system that predicts future performance instead of just rewarding past luck.
The Methodology
1. Statistical Validation
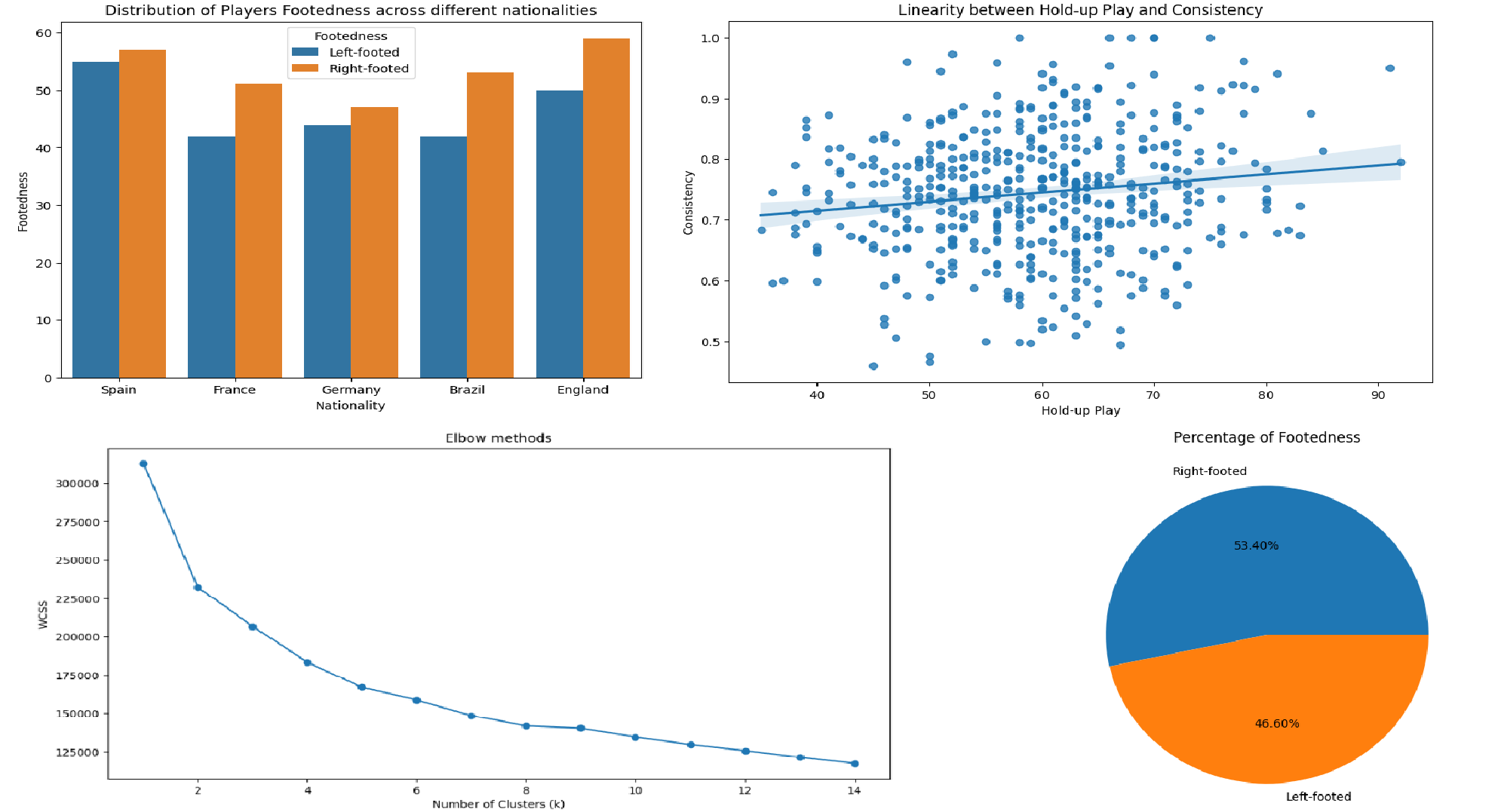
You can't just throw data at an algorithm and hope for the best. I ran Shapiro-Wilk and Levene's tests first to validate the distributions. I proved mathematically that a trait like "hold-up play" heavily correlates with long-term consistency.
2. Feature Engineering
Raw stats are too noisy. I engineered a custom "Total Contribution Score" that weighted goals, assists, and dribbles into a single, clean metric. This gave the clustering algorithm a much sharper signal to process.
3. Clustering & Classification
I deployed K-Means to naturally divide the 500 strikers into two distinct tiers: Elite and Regular. From there, I trained a Logistic Regression model to accurately classify any new player into these buckets based on their stats.
The Deliverables
Key Findings
Hold-up play is the hidden engine.
The regression model proved that a striker's hold-up play is a massive predictor of their overall consistency (a 0.55 correlation). It isn't just about shooting; it's about keeping the possession alive in the final third.
The math defines the elite.
The K-Means algorithm naturally found the breakpoint without human bias. The "Elite" strikers clustered tightly around an average contribution score of 212. The logistic regression model easily learned this threshold and classified players with high accuracy.
Next Steps: A scouting dashboard.
Jupyter notebooks are great for data scientists, but terrible for football coaches. My next step is wiring this Python model into an interactive Power BI dashboard so scouts can drag sliders and interact with the predictions visually.